

Vibe Coding
Machine Learning Scientists Should Embrace It


Vibe Coding has become a buzz word since Feb 2025 when Andrej Karpathy introduced the concept on X. In March, TechCrunch reported that YC's winter 2025 cohort startups have codebases that were generated mostly by AI. It has gained traction in many circles. It excites both critics and proponents alike.
I found a primer for Vibe Coding from IBM. The basic idea is that with the advancement of AI, coder assistants, and that common IDEs have incorporated coding assistants such as Github’s Copilot, one does not need to know how to code to be able to produce functional code that might be ready for production.
Andrej Karpathy explained in his original X post:
There's a new kind of coding I call "vibe coding", where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It's possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good. Also I just talk to Composer with SuperWhisper so I barely even touch the keyboard. I ask for the dumbest things like "decrease the padding on the sidebar by half" because I'm too lazy to find it. I "Accept All" always, I don't read the diffs anymore. When I get error messages I just copy paste them in with no comment, usually that fixes it. The code grows beyond my usual comprehension, I'd have to really read through it for a while. Sometimes the LLMs can't fix a bug so I just work around it or ask for random changes until it goes away. It's not too bad for throwaway weekend projects, but still quite amusing. I'm building a project or webapp, but it's not really coding - I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.
I took his words and made the following illustration:
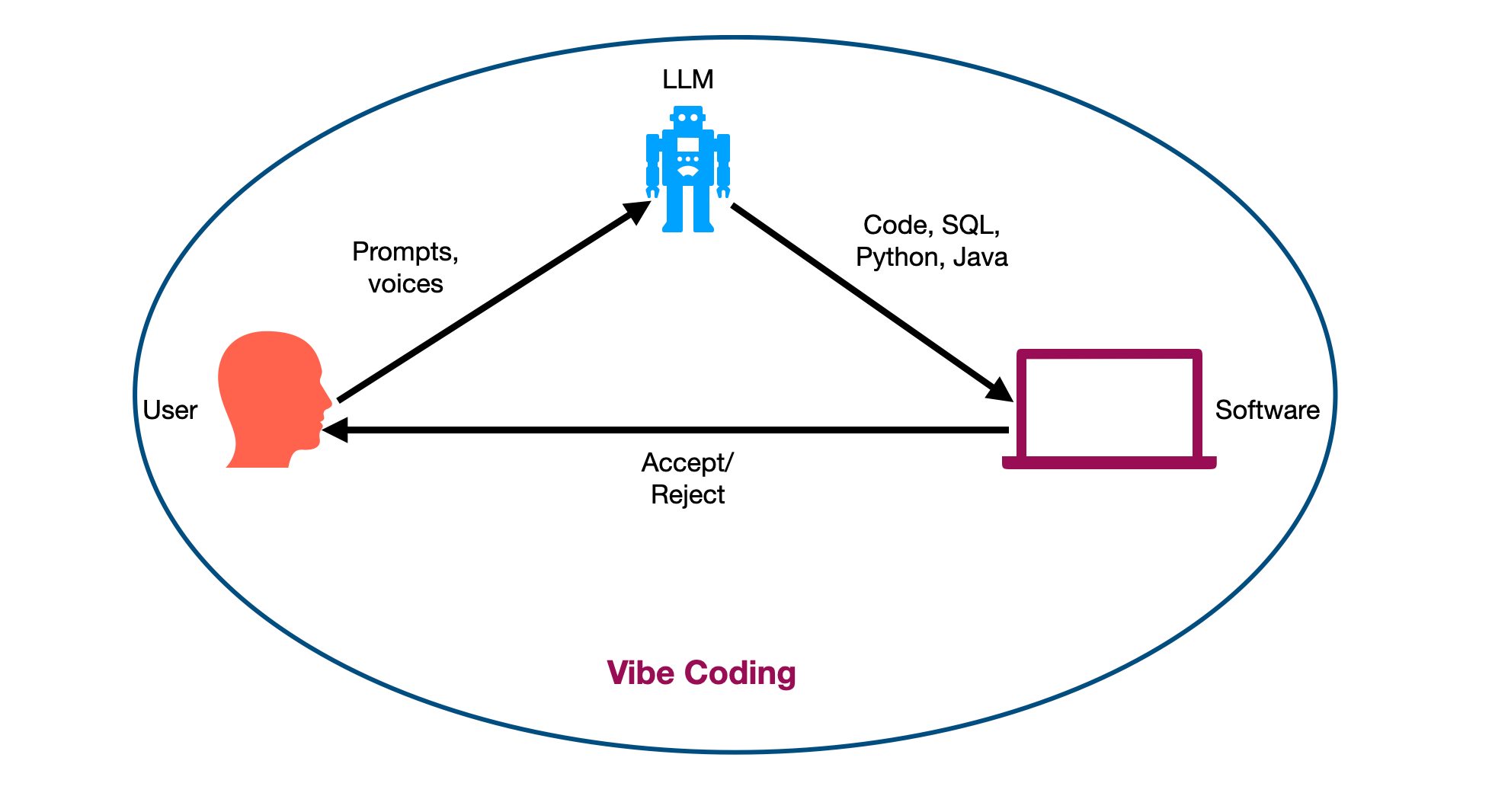
Essentially, a user interacts with an AI powered by LLM to generate code (java, python, SQL, etc). They then accept or reject that piece of code by reading it, or running it through some test programs. Whatever they are not happy with they can use prompt engineering or a voice assistant to interact with the LLM code generator. Everything happens via natural language. No code is generated by the user at all. Code is generated, fixed, and debugged by the LLM. Andrej Karpathy himself said that vibe coding is good for “throwaway weekend projects.” He didn’t make a prediction that people actually would use this in the production environment.
In this blog post, I argue that machine learning scientists (ML scientists) such as machine learning engineers, data scientists, and researchers should embrace vibe coding in their workflow. However, relying on vibe coding word-for-word as what Andrej Karpathy suggested will eventually deskill you in regard to coding. Thus, I recommend that ML scientists use vibe coding in the exploratory steps, then read through the code, create unit tests, and rewrite certain parts for production ready software. Furthermore, when a repo is made public as a result of a research project that employs vibe coding as part of the scientific process, make it known to the community.
Trust LLMs to produce reliable code
If you know what you’re looking for, then vibe coding is a good exercise. I remember working as a data scientist and doing a lot of (ad hoc) data analysis and first level prototyping. I was literally a Jupyter Notebook engineer, writing one note book at a time. It was a lot of time rewriting certain pandas commands, looking up how to conduct certain statistical tests. For every cell of the notebook that I was writing, I had to do a few Google searches to verify its correctness as well as the statistical tests I wanted to use actually do it was supposed to do.
This way of working as a data scientist reminded me of how I would write as a sociologist. As a social scientist under the pressure of the publish or perish culture, I would open a blank word document every day, stared at it, and started thinking about what to write at the beginning of each writing session. Then I would meander into what I actually thought about the topic, my position, what I would argue for, and also conduct some web research on the side. As one of my favorite writing professors said, “I will know what I think about subject ABC by the end of the writing session.“ In other words, writing is thinking. Writing helps the writer articulate their thoughts in precise terms, clear up any uncertainties, and understand their position in a particular debate.
Similarly, as a data scientist I understand the subject matter, a statistical test, a business challenge by first staring at blank Jupyter Notebook, writing one test at a time, writing one line of code at a time, building one ML model at a time. This process helped me dissect a business problem, and figure out how to solve it using ML tools. The process is relatively messy, and one has to iterate many times.
In this scenario, I think vibe coding is really helpful. If I know what I was looking for, I should either write a prompt such as “use the given data file data.csv, perform feature engineering on all the features, and train an XGBoost model taking click through rate as the target variable and the remaining features as predictive features. Calculate the precision, recall at the end.“ I hope at the end, a Jupyter notebook or a model.py file would be generated, and I can look through the code to understand how the AI would generate code differently that what I would have done manually. If this is exactly what happened the prototyping time would reduce significantly. Instead of writing one line of code at a time, I essentially would become an evaluator, verifying the correctness of the code, and the analysis.
Another way of mini vibe coding is to generate one Jupyter Notebook cell at a time. This is possible if one is creating a Jupyter Notebook using VSCode. This is powered by Github’s Copilot. In my experience, Github copilot is more of an autocompletion than a total code generation where you would write a prompt, or a code and copilot would generate the next code block for you. The ML scientist still has to make sense of the entire structure from the beginning to the end of the code. Think of a software as an essay. Copilot tends to generate one paragraph at a time instead of generating the entire essay for you. This version of mini vibe coding is being used on a daily basis. Sometimes I use it to save time. However, because my attention is limited, I often prefer Copilot to generate fewer than 10 lines of code such that I could skim through and approve quickly.
What I have not tried is to simply prepare some data, prompt an LLM to conduct the analysis, build the model, and calculate precision and recall for me. I guess, it should be able to do such a procedure since ML model development workflow is relatively well defined.
Iterate over the LLM-generated Code for Production
When I became an ML engineer, I realized the difference between what an ML engineer does and what a data scientist does is in the productionization aspect of the ML workflow. ML engineers are essentially software engineers with some ML background. In contrast, data scientists are statisticians and machine learning scientists who happen to also code. In other words, the emphasis of the first category is in shipping products while the emphasis for the later job category is in the ML development aspect. ML engineers write more production-ready code. They also write more unit tests. In my experience the idea of “test-driven development“ is more of a daily practice for MLEs than for data scientists. Data scientists can explore more, while MLEs are more driven towards production.
With this distinction in mind, when it comes to vibe coding and production, one has to be very careful with what the LLM has written. The human in the loop here, i.e. ML scientists (MLEs or DS) has to control the quality of the code, knowing where the code would break in production and how to fix it. This comes with practice.
There is no such thing as vibe debugging, vibe troubleshooting, vibe code review, or vibe test-driven development. Vibing is fun and useful in the early exploratory phase of model development. But once the model is locked in, software development has to follow the standard rigorous process of test-driven development, meaning the software has to pass unit tests, and approved by someone (maybe an AI agent in the near future).
Using LLMs to write Unit test
At least unit tests are something that LLMs can help with. All MLEs are to a certain extent QA (Quality Assurance) engineers. Maybe here is where vibe coding can also help MLEs to quickly prototype QA tests for their models to make sure that they would perform well in practice, once it’s put in production.
On the Risk of Deskilling
Critics of vibe coding, and LLM-assisted coding in general point out that by relying on LLMs to generate one’s code, one loses intimacy with the code being written, and therefore losing the knowledge of what is being generated. This is a real risk. Currently, junior software engineers are having a hard time to find a job because companies assume that they might not be as good as LLMs which have been trained on millions of pieces of code generated by experienced coders on the internet. Why hiring someone who cannot code as well as an AI? Basically the door is closed on junior programers who would want to debug code in the real work environment. So as a whole industry, people are being deskilled one group at a time.
How about experienced MLEs and data scientists, are they also being deskilled if they rely too much on LLMs, and AI to generate their analyses and production code. Possible.
One of my friendss when being asked if he was using AI to generate SQL queries, he answered that AI annoyed him, and slowed him down. He had a vision of what to accomplish in mind, AI tended to interfere with his thought process. His approach to data engineering is relatively top-down, while AI tool tends to vibe as in writing with the flow. AI has some good ideas every once in a while, but its net effect is negative for my friend because it slowed him down since he couldn’t bother to articulate his entire complicated thinking in words. It’s faster to write code. He even told me once: code doesn’t lie. So just look through the code.
In my experience with data engineering, AI is not as helpful as I thought it would. The main reason is that as a subject matter expert (SME), I know precisely which feature matters for what model, while AI lacks this crucial context. By typing a very elaborate prompt to help guide AI, I actually slow myself down because it takes me even less time to just write the code myself. To be clear, and precise in prompting means to add more context. This sometimes means generating a huge chunk of texts which might be even longer than the SQL query itself. So why would I bother to describe what should be done? I could simply just write the query myself given the time constraint.
Conclusion
I think vibe coding has a role to play in the workflow of MLEs and data scientists. However, I only see that it’s good at the beginning in the early exploratory period of a piece of code or a project. Once the initial code has been generated in order to put it through production, code review, the human worker still has to scrutinize the accuracy of the code generated. This might lead to some amount of deskilling. Yet, I think our skills will be shifted to testing, quality control, and refining requirements. However, these all take practice, scrutinizing LLM-generated code takes time, and patience.
Thanks for sharing! I really appreciate your thoughts on how to approach vibe coding, especially on the risk of deskilling. I’ve been thinking about similar issues with LLMs more generally and trying to find a good balance in how I use them. Your take really resonates with me.